
あなたはストレージの責任者であり、開発者とデータベースの人がカフェインを飲む前に早朝にあなたの机にやって来て、ストレージが遅すぎるのであなたがする必要があるとあなたに言い始めたことがありますか?それについて何か? 私が持っています。 私の意見では、仮想化の担当者がやって来て同様の告発を行うとさらに悪化しますが、それは別の話です。
LogicMonitorで働いているので、これはいつも見ています。 「NetAppsが遅い」という理由で人々が私たちのところにやって来ます。 実際にはESXホスト自体であるか、クエリの設計が不十分なためにSQLサーバーで問題が発生していることがよくあります。 私はLogicMonitorで働く前にこれを直接経験したので、これが定期的な問題であることは私にとって驚くことではありません。 この問題を自分で経験したとき、ボトルネックがどこにあるかを実際に把握できるように、関連するすべてのシステムを監視することが重要であることがわかりました。
分解してみましょう…。
開発者は次のように述べています。「ディスクが私のアプリを殺しています。 高速化するにはディスクを追加する必要があります。そうでない場合は、より優れたストレージシステムを入手する必要があります。」
開発者がそのような告発をしたとき、あなたはどうしますか? あなたは確かに新しいディスクシステムに$ 100を落とすことができます、しかしそれが本当に問題を解決するだろうと誰が言いますか? 開発者? あなたはその電話をかけるために開発者を信頼しますか? あなたは運用担当者であり、さらに具体的にはストレージ担当者です。 あなたがこの電話をかける人でなければなりません。 ストレージ担当者として、私はすぐにアプリまたは アプリケーションの データベースが提供されていて、最初の主張が当てはまるかどうかを確認するためだけに、パフォーマンスがどのように見えるかを確認します。
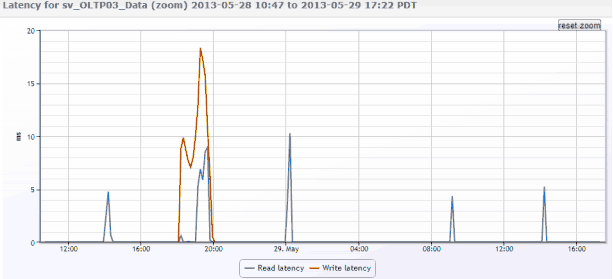
データを表示した後、開発者に次のように言います。「私にはNetAppのようには見えません。 データベースをチェックしましょう」。
そして、データベースメトリックを確認すると、この興味深いグラフが見つかります…。
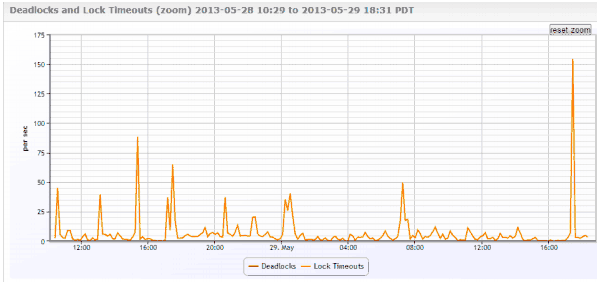
したがって、「これらのロックタイムアウトは私には興味深いようです」と言うかもしれません。
そして、あなたは両方ともデータベースの人にさまよっています。 あなたの一人がたまたまデータベースの人なら、さらに良いでしょう。 スペシャリストがいる場合でも、スペシャリストの基準点があるので問題ありません。 徹底的な監視のおかげで、ディスクの待ち時間は問題ではないと判断し、データベースサーバーで何かおかしなことが起こっていることに気づきました。
この特定の例では、たまたま幸運に恵まれ、問題の原因となっているクエリまで追跡することができました。 そもそもやって来た開発者が問題を担当していたことが判明し、彼はそれを修正することができました。
このシナリオでは、私(および私のチーム)は、ストレージプラットフォームとデータベースアプリケーションの両方を同じ監視プラットフォームに配置できたので、問題を見つけて解決策を実装するのがはるかに簡単になりました。 私のアドバイス:関連するすべてのプラットフォームが同じ監視ソリューション(物理サーバーと仮想サーバー、ネットワーク、ストレージ、アプリケーション)に含まれていることを確認してください。 すべての関係者にデータへのアクセスを許可します。 指先ではなく、お互いにコラボレーションします。 組織が問題をより迅速に解決し、最終的にはITニーズの実現により成功することがわかると思います。