

ダウンタイムなしで 10,000 以上のコンテナーをアップグレードする方法!
Kubernetes のバージョン アップグレードの管理は、手ごわい作業になる可能性があります。 API のバージョンは段階的に変更され、新しい機能が追加され、既存の動作は廃止されます。 バージョンのアップグレードは、Kubernetes プラットフォームが必要とするアプリケーションにも影響を与える可能性があります。 Pod ネットワークや DNS 解決などのサービスに影響を与えます。 LogicMonitor では、反復可能な方法でコラボレーションとデュー デリジェンスを浸透させるように設計されたプロセスを通じて、Kubernetes のバージョン アップグレードが確実に成功するようにしています。 Kubernetes アップグレードのベスト プラクティスに飛び込みましょう。
内訳:
マネージド AWS を実行しています EKS 私たちの環境のクラスター。 EKS クラスターには AWS が管理するコントロール プレーンがあり、Kubernetes のバージョン アップグレードが開始されると、AWS が代わりにコントロール プレーン コンポーネントをアップグレードします。 ワークロードは、管理ノード グループと自己管理ノード グループの混合で構成されています。 Kubernetes のバージョン アップグレード中に、AWS は インスタンスのリフレッシュ 管理対象ノード グループで。 自己管理ノード グループをアップグレードするには、 インスタンスのリフレッシュ. ノードが封鎖され、ポッドが正常にドレインされるようにするために、 aws-ノード終了ハンドラー. 以前のバージョンの Kubernetes を実行しているノードがドレインされて終了すると、新しいインスタンスが代わりにアップグレードされた Kubernetes バージョンを実行します。 このプロセス中に、グローバル インフラストラクチャ全体で何千ものコンテナが再作成されます。 この再作成は、アップタイム、アクセシビリティ、またはアプリケーションのパフォーマンスに影響を与えない速度で行われます。 アップグレードします Kubernetes クラスター ダウンタイムがゼロで、本番ワークロードへの影響もありません!
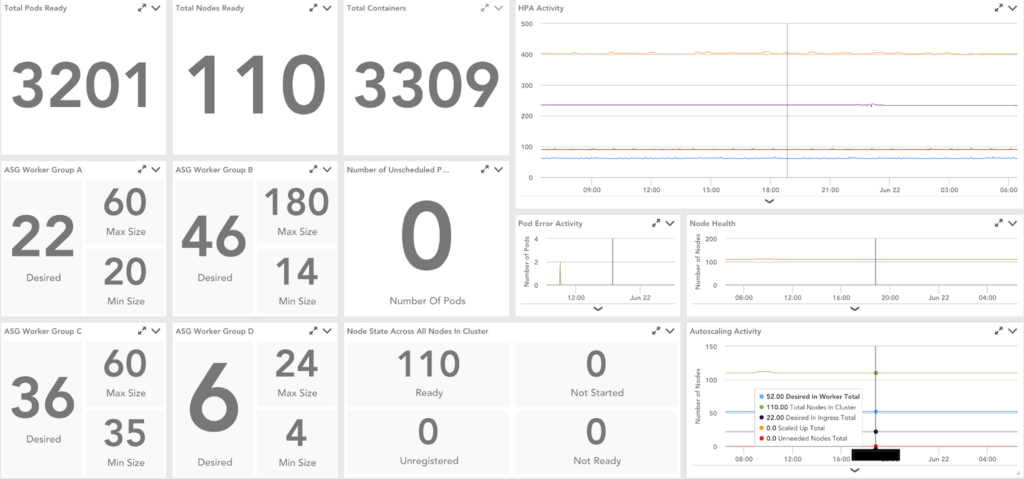
Kubernetes のバージョン アップグレードを監視する際に特に役立つことがわかったデータポイント:
- Auto Scaling グループのメトリクス
- 必要なインスタンス数
- 最大サイズ
- 最小サイズ
- 合計ノード
- クラスター オートスケーラーの指標
- スケジュールされていない Pod の数
- 削除された Pod の数
- 準備ができていない状態のノードの数
- 起動していないノード数
- Ready 状態のノード数
チーム
バージョン アップグレードは、以下に説明するプロセスで特定の役割を果たす XNUMX 人のエンジニアのチームによって実行されます。 Ops(New)、Ops(Lead)、Ops(Sr):
オペレーター(オンボーディング) オプス(新規)
このオペレーターは、Kubernetes のアップグレード サイクルの新機能です。 チームの新しいメンバーとしての主な目標は、アップグレード プロセス全体に慣れることです。 過去のアップグレードを調査し、プロセスを学び、現在のアップグレード作業をサポートします。 この役割では、オペレーターは、研究開発の Ops(Lead) を担当するオペレーターの指導の下で、実稼働クラスターと非実稼働クラスターの両方でアップグレードを実行します。
コア業務
- 開発/本番前クラスターでのプロセスの実行を担当
- 本番クラスターでのプロセスの実行を担当
オペレーター(リーダー) オペレーション(リード)
このオペレーターは、アップグレード サイクル中のリード エンジニアです。 彼らは、変更の調査、重要なコンポーネントのアップグレード、重大な変更に対する一連のアクションの決定、およびすべてのクラスターのアップグレードのスケジューリングを担当します。 このエンジニアが提案する変更の計画には、かなりの時間が費やされます。 このオペレーターは、さまざまな利害関係者間の連絡役としても機能します。 これには、重要な日付、興味深い調査結果、機能の廃止などを伝えることが含まれます。 Ops(Lead) は、必要に応じて、Ops(New) と Ops(Sr) の間の知識伝達セッションを調整します。 前のサイクルでは、このオペレーターは運用 (新規) として参加し、開発クラスターと運用クラスターの両方でアップグレード プロセスを実行した経験があります。
コア業務
- このオペレーターは、前のサイクルでは Ops(New) でした。その経験を活かして、Ops(Lead) には実行タスクの理解が求められます。
- 開発/本番前クラスターでのプロセスの実行を担当
- 本番クラスターでのプロセスの実行を担当
- バージョンアップ変更のコアリサーチを担当
- Ops(New) と Ops(Sr) の間の関連作業の調整を担当
オペレーター(シニア): オペレーション(シニア)
このオペレーターは、過去 XNUMX 回のアップグレード サイクルに参加していました。 このエンジニアは、運用 (リード) と運用 (オンボーディング) の両方の知識リソースとして機能します。
コア業務
- 前のサイクルのこのオペレーターは Ops(Lead) であり、その経験を活用して、Ops(Snr) は Ops(Lead) と Ops(On-boarding) のメンターとして機能します。
- 本番クラスターでのプロセスの実行を支援する責任があります。
プロセス
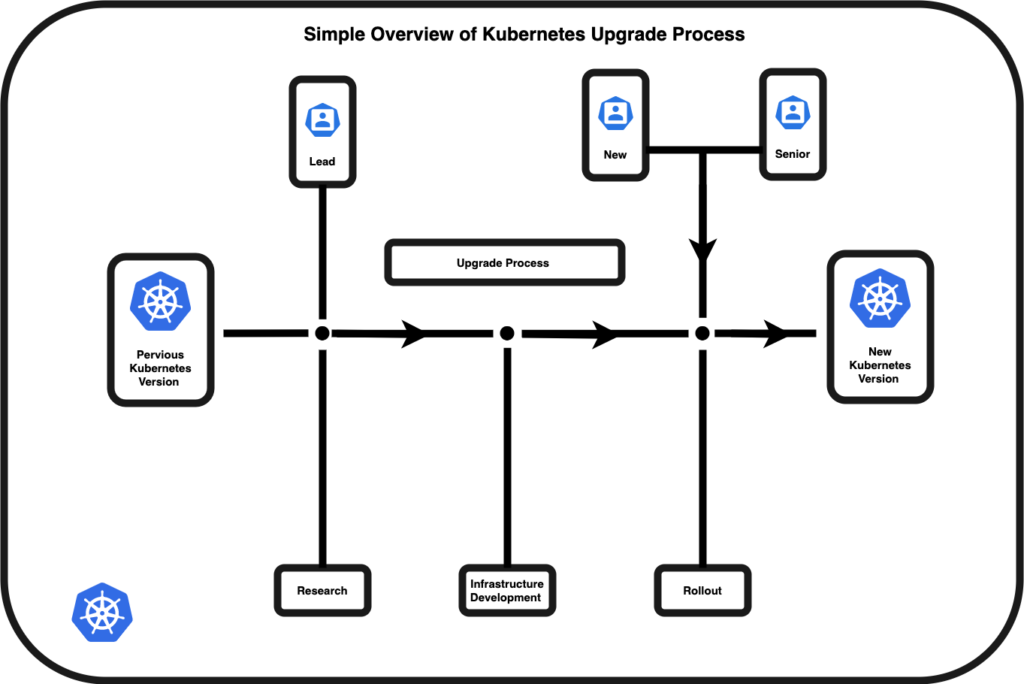
研究: 主任オペレーターは、現在のバージョンとアップグレードしたい提案されたバージョンとの間の変更を調査することからサイクルを開始します。 この作業フェーズでは、リード オペレーターが調査結果、障害物、関心のある項目をコア チームと共有します。 主任オペレーターを支援するために、以前のアップグレード サイクルの過程でいくつかのリソースが収集され、実行予定のリリースでどの Kubernetes コンポーネントが変更されたかを判断するのに役立ちました。 主任オペレーターは、これらのリソースを使用して次の質問に答えます。
- 質問
- 懸念すべき API は卒業または廃止されましたか?
- デフォルトで有効になっている機能で、考慮すべき、または Kubernetes の実装で活用できるものはありますか?
- クラスタで現在実行されているコンポーネントは、Kubernetes のバージョン アップグレードの影響を受けますか?
- リソース
重要なコンポーネント: クラスター内のいくつかのコンポーネントは、Kubernetes の運用にとって重要であると見なされます。これらの各コンポーネントには、特定の Kubernetes バージョンで実行するための推奨バージョンがあります。 サポートされているバージョンを実行できることを確認するために調査が行われます。
これらのサービスは、クラスターの実行可能性にとって重要であると定義しています
- DNS
- ポッド ネットワーキング
- クラスターイングレス
- クラスタの自動スケーリング
インフラストラクチャの開発と展開: リソース部分が終了すると、リード オペレーターは一連のプル リクエストを生成して、Kubernetes クラスターをサポートするインフラストラクチャを変更します。 これらのプル リクエストは、社内ガイドラインに従って承認されています。
ロールアウトする:
- コミュニケーション: 各ロールアウト中にコミュニケーション スレッドが作成され、アップグレード中に実行された各プロセスの進行状況に関する最新情報がチーム メンバーに提供されます。 問題が発生した場合、これらの通信スレッドを使用して詳細な調査を行うことができます。
- 運用前: 運用前クラスターへのロールアウトが開始されます。 これにより、主任オペレーターは変更を精査し、コンポーネントが異常な状態で見つかった場合の一連のアクションを決定する機会が与えられます。 オンボーディング エンジニアは、これらの運用前のロールアウト中にリード エンジニアを追跡し、リード オペレーターの監督下で運用前のクラスターでロールアウトを実行することが期待されています。
- 本番: 本番クラスターは、XNUMX 回のメンテナンス期間中に更新されます。 従来、この種の変更は、何かが発生した場合にお客様に影響を与える可能性があるため、定期メンテナンス ウィンドウ中に行われていました。 すべてのオペレーターが本番クラスターの展開に参加します。 すべてのノードが新しい Kubernetes バージョンに移行すると、各オペレーターは一連のヘルス チェックを実行して、各クラスターが完全に機能する状態にあることを確認します。
結論として、私たちのアップグレード プロセスは、重要な Kubernetes コンポーネントへの変更を特定し、環境への影響を判断し、重大な変更が特定された場合の一連のアクションを作成することで構成されています。 バージョン アップグレードを実装する準備ができたら、 インスタンスのリフレッシュ これにより、ノードが封鎖され、終了前に Pod が正常にドレインされます。 アップグレード プロセスの管理を担当するチームは、オンボーディングされた各エンジニアによって循環される 3 つの異なる役割で構成されます。 Kubernetes はインフラストラクチャの重要な部分であり、LogicMonitor で設計したプロセスにより、サービスのアップタイムに影響を与えることなく Kubernetes のバージョンをアップグレードできます。

