
幸せな従業員は幸せな顧客と同じであるという古い格言があります。 Forbes、Harvard Business Review、Entrepreneur などの評判の高い雑誌は、この概念を詳しく分析するために多大な知力を投入しており、カスタマー サクセスのリーダーもその真実を認めています。 ビジネスと同じように、IT においても少しの「セルフケア」が大いに役立ちます。 顧客が直面する問題を解決することが常に最優先されますが、顧客により良いサービスを提供するために、ネットワーク運用チームは最高のデータとインフラストラクチャの最も明確な状況を 24 時間年中無休で提供する必要があります。 ネットワーク サービスの問題を最小限に抑え、カスタマー エクスペリエンスを最適化するには、完全な可視性が必要です。 このブログでは、ネットワーク運用チームが直面するいくつかの一般的な課題を検討し、LogicMonitor のプラットフォーム ベースのアプローチがチーム、データ、エンド ユーザーを統合するためにどのように設計されているかについて説明します。
日々の苦労: ダッシュボードの「青信号」は本当にすべてが順調であることを意味するのでしょうか?
通常、ネットワーク エンジニアはネットワーク アクセスのアップグレードと変更を行います。 新しいルーターを追加して、増加したトラフィックに合わせて容量とパフォーマンスを拡張することを想像してください。 ネットワーク チームが共有するハイブリッド クラウド インフラストラクチャ全体の総合的なビューだけが、すべてが正常に実行されており、ネットワークの外部には何も影響がなかったことを確認できます。 定期的なネットワーク アップグレードの後、チームはおそらく、インターフェイス ステータスの変化に伴う警告の急増やエラーが発生していないことを確認するために syslog へのアクセスを要求しなくなるでしょう。 定期的なアップグレードでは、通信する必要がある新たな単一障害点のチェックにかかる時間を保証できません。また、ネットワーク トラフィックを分析して速度の低下、遅延、または極端な帯域幅の使用状況を特定することもできません。
ツールはあなたの日常生活に活力を与えるものでなければなりません。 重要なビジネス会議や初めてのデートの前に鏡で自分をチェックするのと同じように、定期的にアップグレードするたびに監視プラットフォームをチェックして、すべてが時計のように機能していることを確認する必要があります。 モニタリング プラットフォームは、日常的な変更が行われるたびに、たとえチェックするつもりがなかったものであっても、ネットワーク運用へのあらゆる影響を表示する必要があるため、自信を持ってネットワークを拡張できます。 その自信は、社内チームとエンド ユーザーの両方にとって大きな助けとなります。
より大きなブリップ: 優先順位を変更せずにネットワーク警告を修正するのは簡単であるはずです
Citrix NetScaler VPX はいくつかの警告アラートをトリガーしますが、一見するとこれは P1 の問題ではないため、チームはスケジュールされたプロジェクトから変更するかどうかを決定する必要があります。 アラートは、顧客がアプリケーションにアクセスするのを困難にする可能性があるパケット損失の増加を示します。 計画的なダウンタイムはなく、明らかな構成の問題も見当たりません。 したがって、これが永続的な解決策ではないことを承知して、デバイスを再起動してパケット ドロップの問題を一時的に軽減します。
このシナリオでは、可視性の欠如に依存するいくつかの課題が生じます。 メトリクスを確認して、大規模な停止が発生していないことを確認することしかできません。 このような複雑な状況では、インフラストラクチャの残りの部分に関連付けられたネットワーク トラフィック ビューと syslog データにアクセスして、すべてのネットワーク パスを完全に可視化する必要がありますが、これには通常、アクセスするには時間がかかりすぎます。 トレードオフを行わずに、明確なトラブルシューティング ワークフローを使用して、警告を簡単に解決できるべきではないでしょうか? これらのネットワークの問題を解決することは、「どちらか一方」のトレードオフ シナリオであってはなりません。 「はい/はい」である必要があります。 統合監視ソリューションでは、トラブルシューティングのワークフローを効率化するために、すべての監視リソースのネットワーク メトリックとログへのアクセスを提供する必要があります。
本格的なインシデント: 可視性が不可欠になります
あなたのチームは、障害が発生した Azure VM 内の重要な Windows アプリケーションをサポートしています。 アプリがクライアントの要求に応答しなくなり、ネットワークの輻輳やパケットのドロップが発生します。 SD-WAN 制御のネットワークでも中断やパフォーマンスの低下が発生し、顧客にとってはさらに悪化します。 監視ダッシュボードにはアラートが表示され、サポート チームには顧客からの問い合わせが増えます。
サーバー障害が発生すると、ハイブリッド クラウド環境全体の完全な可視性は「あれば便利」ではなくなります。 ネットワーク運用がデータセンターを超えてクラウド管理テクノロジーにまで拡大するにつれ、可視性のギャップを埋めてリスクを軽減するには、最新の監視プラットフォーム内であらゆる IT デバイスとクラウド サービスのパフォーマンスを統合して接続することが重要になります。
LogicMonitor の統合プラットフォームにより、ネットワーク運用チームはインフラストラクチャを完全に制御して、定期的なアップグレード、ネットワーク警告、または重大なインシデントが顧客に与える影響を最小限に抑えることができます。 LogicMonitor がこれらの危険なシナリオを軽減する XNUMX つの方法を見てみましょう。
包括的なネットワークの可視性
- LogicMonitor は、ネットワークについて知る必要があるすべてを検出します。 ネットワーク インフラストラクチャの維持と最適化に必要な監視、アラート、グラフを数分以内に作成できます。 オンプレミス、データセンター全体、またはハイブリッドおよびマルチクラウドで管理される SD-WAN デバイスなど、最も複雑なネットワークでも必要なカバレッジを実現します。
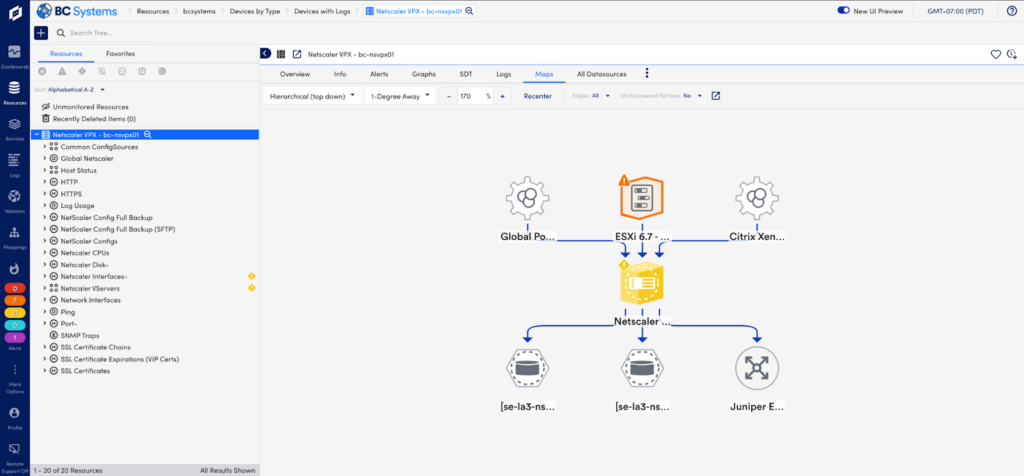
- 自動生成されたトポロジ マッピングを使用してネットワークを視覚化します。 LogicMonitor は、重要なインフラストラクチャ リソース間の関係を検出してマッピングします。 継続的なネットワーク検出により、最新の構成がチェックされ、プラットフォーム内の意味のある動的なグループにデバイスがグループ化されます。
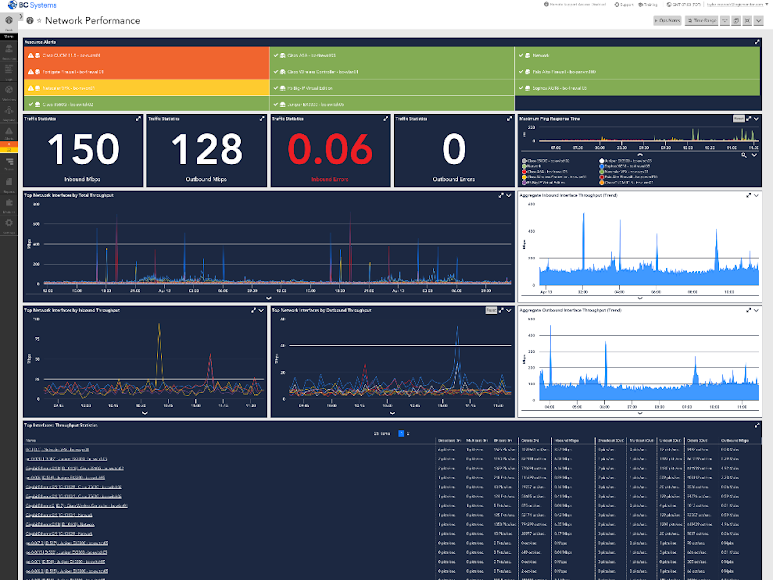
ハイブリッド クラウド インフラストラクチャ全体の共有ビュー
- LogicMonitor は、サービスごとに一目でわかるステータス ダッシュボードを自動的に作成するため、情報の共有が容易になり、チームにパフォーマンスと傾向を常に知らせることができます。
- 可視性を高め、インフラストラクチャ スタック全体のデータを結合してサービス固有のビューを作成し、ServiceNow などの IT サービス管理ツール、PagerDuty などのインシデント通知ツール、Slack や MS Teams などのエンタープライズ コミュニケーション プラットフォームの組み込み統合を使用してトラブルシューティングに協力します。
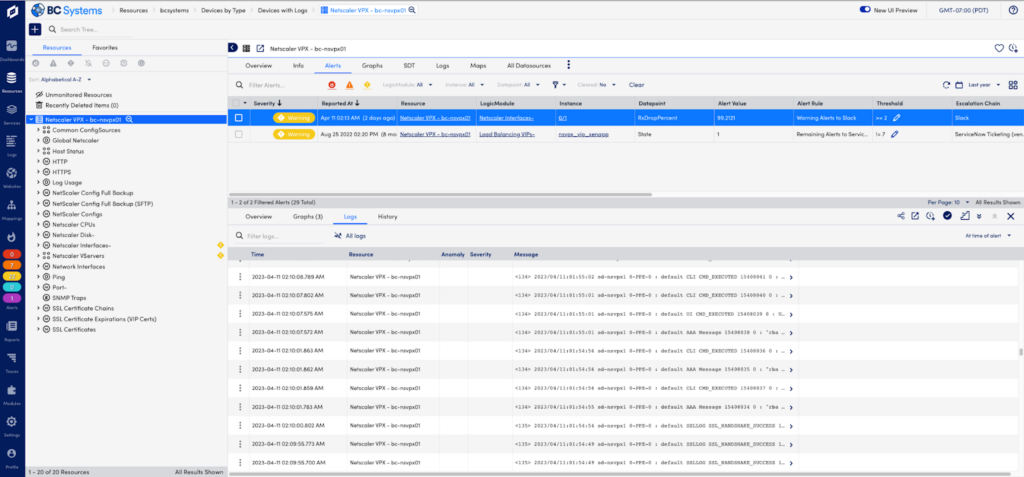
ネットワークの監視とトラブルシューティングのワークフロー
- LogicMonitor は、ネットワーク チーム向けに構築された合理化された監視とトラブルシューティングのワークフローを提供します。 組み込みの異常検出により、単一のプラットフォームですべての監視対象デバイスのメトリクスとともにネットワーク syslog にアクセスし、即座に洞察を得ることができます。
- メトリクスベースのアラートは、異常値の調査が必要な場合に、適切な条件で適切なチームに送信され、アラートが送信されます。 各アラートでは、影響を受けるデバイスを示すトポロジ マッピングを含むネットワークおよび IT ログのインライン ビューが提供されます。
統合された可視性、統合されたチーム、幸せな顧客
私たちはその格言を採用し、IT 向けに修正しています。ネットワーク、インフラストラクチャ、クラウド、アプリ全体の包括的な可視性をチームに提供して、トラブルシューティングを迅速化し、リスクを軽減し、顧客の満足度を維持できるようにします。 ネットワーク運用全体にわたって存在する可能性のある可視性のギャップを考慮し、それらのチームに単一の監視プラットフォームを装備して、チームが協力して MTTR を削減し、優れたブランド エクスペリエンスを維持できるようにします。 LogicMonitor を使ってみましょう。

