
このホワイト ペーパーでは、次の XNUMX つの関連する結果を確実にするためのアラート チューニングのベスト プラクティスを提供します。
1. 重大な状況を把握し、適切な担当者に警告するための監視が実施されています
2. 騒音が減り、不必要に起こされない
これらの結果は、監視戦略を成功させるために不可欠です。 以下は、新しい監視システムを設計するとき、または既存のシステムをレビューするときに考慮すべきいくつかの重要な問題です。
監視項目の構成要素
監視ソリューションが異なれば、監視項目を表す用語も異なります。 通常、データセンターなどの高レベルのグループと、その下の低レベルのグループおよび個々のホストを含む階層システムがあります。 ホスト レベルには、ディスク、CPU などの監視カテゴリがあり、その下には /dev/sda が / にマウントされているなど、監視対象の特定のインスタンスがあります。
監視ソリューションの組織構造がどうであれ、監視対象の各アイテムには次のコンポーネントが定義されている必要があります。
• メトリック: CPU の使用率など、監視されている測定値。
• しきい値: メトリックが最適ではない状態にあると見なされる場合の定義。
• アラート レベル: 特定の状態に関連付けられた緊急度のレベル。通常は、警告、エラー、またはクリティカルです。
• 解決するアクション: アラートに関連付けられたアクション アイテム。
監視ソリューションを開発する際に上記のコンポーネントを考慮しないと、アラート システムに障害が発生する可能性が高くなります。 アラート システムは、あまりにも多くのノイズを生成すると機能しなくなり、スタッフが重要なアラートを見逃したり無視したりする可能性がありますが、柔軟性の欠如、監視機能、または不適切な構成のいずれかが原因で重要な状況を把握できなかった場合にも機能しなくなる可能性があります。
監視システムを展開するときに正しいしきい値を設定するのは難しい場合があります。 優れた監視ツールには、すぐに使用できる適切なデフォルトがありますが、これらは時間の経過とともに調整する必要があります。 たとえば、96% の CPU 使用率はすべてのシステムにとって必ずしも悪いことではありませんが、一部のシステムではそうなるでしょう。 さらに、一部の監視ツールは、履歴メトリック測定に基づいてアラートのしきい値を自動的に構成する機能を提供します。 これにより、しきい値のベースラインが提供され、しきい値の傾向に基づいて将来の問題が理想的に予測されます。
アラート レベルも、時間をかけて調整する必要があります。 繰り返しますが、適切なデフォルトは役に立ちますが、あるシステム セットでの警告アラートが他のシステム セットでの重大なアラートになる可能性があります。
アラートが無視される原因となる最も一般的に見落とされがちな要件の XNUMX つは、アクション アイテムを定義する必要があることです。 優れた監視ソリューションには、特定の状態の原因を示す合理的なデフォルトの説明があります。 私の好みの監視ソリューション LogicMonitor では、CPU 使用率に関するアラートに関連する次のメッセージが表示されます。
「server5 の 123 分間の負荷平均は現在 99 であり、重大な状態になっています。 これは 2016 年 05 月 11 日 11:38:42 PDT に開始されました。 どのプロセスが CPU を消費しているかを確認します (「ps」コマンドを使用して、実行可能で待機状態にあるプロセスを確認します。「top」コマンドを使用すると、個々の CPU コアの使用状況が表示されます)。 トラブルシューティングを行うか、しきい値を調整してください。」
デフォルトのメッセージとして、これは非常に便利です。 トラブルシューティングの基本的な手順を受信者に伝えます。 これらのメッセージは、より多くのアプリケーション サーバーをクラスターに追加する必要がある高トラフィックなどの既知の状況に合わせてカスタマイズできます。 実行可能な応答がない監視アラートの実装は避けてください。 これは単にノイズを増やし、アラートを受信する人々の不満を増大させます。
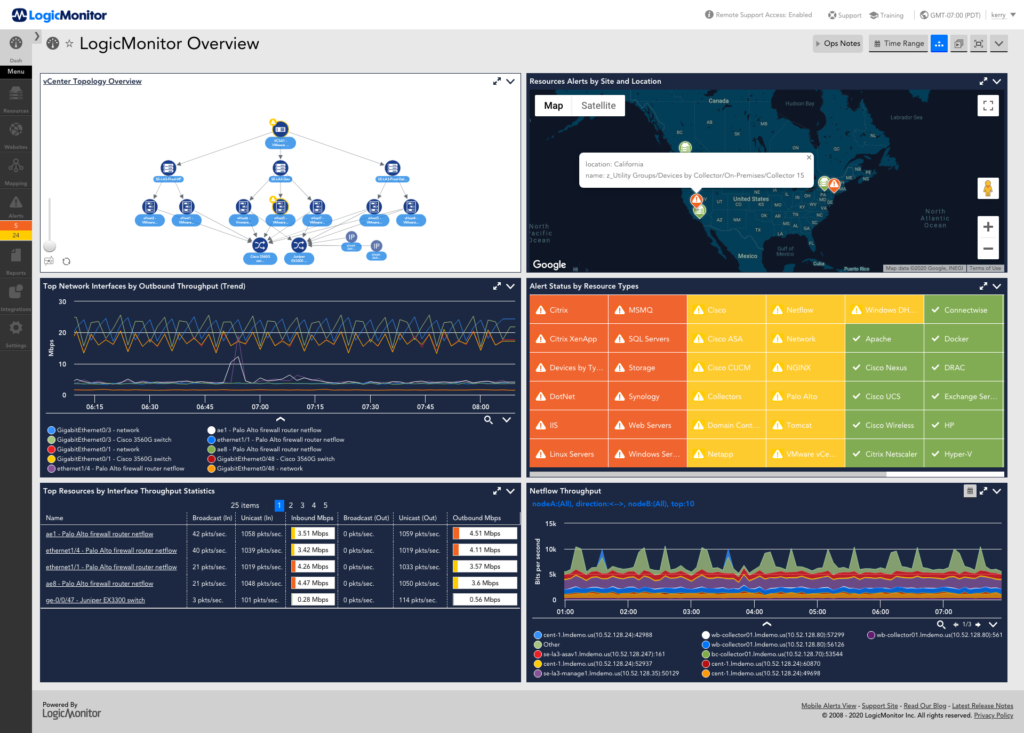
アラート スパムを回避する
頻繁に発生するアラートが多すぎると、アラート スパムまたはアラート ストームと呼ばれることもあります。 これは非常に危険であり、システム監視の失敗など、多くの悪影響をもたらす可能性があります。 アラートが多すぎると、実際に重大な問題が見過ごされる可能性があります。 アラートが多すぎると、ノイズを削減するために重要なアラートが誤って無効になる可能性もあります。 すべてのアラートは意味があり、アクションが関連付けられている必要があります。
アラートを正しくルーティングすることも重要です。 アクション アイテムが誰かに電話をかけることである場合、アラートは意味がありません。 管理者を受付係に変えないでください。 これは、オンコールの開発者とさまざまなシステムを担当するさまざまなチームがいる DevOps 文化で作業する場合に特に重要です。 特定のメトリックはアプリケーション レイヤーの問題を示し、開発者は状況を解決するのに最も適していますが、データベースに関連する問題は DBA が処理する必要があることを考慮してください。 運用担当者がシステム障害の最前線に立つのは理にかなっていますが、彼らの唯一の行動項目が開発者または DBA に電話することである場合、これはすぐに意気消沈する可能性があります。 同様に、開発者が明らかにシステム障害で目が覚めた場合、これも問題になる可能性があります。 あるチームが別のチームにエスカレートしなければならない状況は常にありますが、これらは標準ではなく例外であるべきです。 LogicMonitor では、問題が発生したときにアラートを適切な担当者にルーティングするカスタム エスカレーション チェーンとアラート ルールを設定することで、アラート スパムを回避できます。
ダウンタイムの管理
選択した監視ソリューションには、ダウンタイムを設定するためのきめ細かい制御が必要です。 これは、完全なダウンタイムの展開中にすべてのアラートを無効にすることから、継続的なメンテナンスのために個々のホストと監視対象のインスタンスを制御することまで、さまざまです。
たとえば、ダウンタイムに対するきめの細かいアプローチにより、特定のホスト上の単一のハード ドライブのダウンタイムを設定できます。 現在実稼働していないホストについて誤ってアラートを受け取った場合は、すべてのメトリックを無効にすることを決定できますが、それでもホストが稼働していてネットワーク ping に応答していることを確認したい場合があります。 さらに、ホストのすべての監視を無効にすることが望ましい場合があります。 たとえば、ホストが実稼働クラスターから削除されたが、完全には廃止されていない場合、監視する必要はないと判断できます。
ホスト グループは、関連するシステムのグループを管理するのに役立ちます。 たとえば、開発、QA、および生産グループは、ダウンタイムを管理するための優れた高レベルの組織を提供します。これは、QA 展開中に QA グループ内のすべてのホストを無効にすることを決定する場合があるためです。 自動展開の場合、優れた監視システムは許可する API を提供します。 自動化ツール ダウンタイムを指定します。 スケジュールされたメンテナンスの場合、モニタリング ソリューションにより、繰り返し可能なメンテナンス ウィンドウを事前にスケジュールできる必要があります。
ダウンタイムは、可能な限り詳細なレベルでスケジュールする必要があります。 たとえば、ディスクのサイズを増やす場合は、ホスト全体をダウンタイムに設定しないでください。 問題の修正に 24 時間かかることがわかっている場合は、24 時間のダウンタイムをスケジュールします。 設定を忘れないように、ダウンタイムは自動的に期限切れになります。
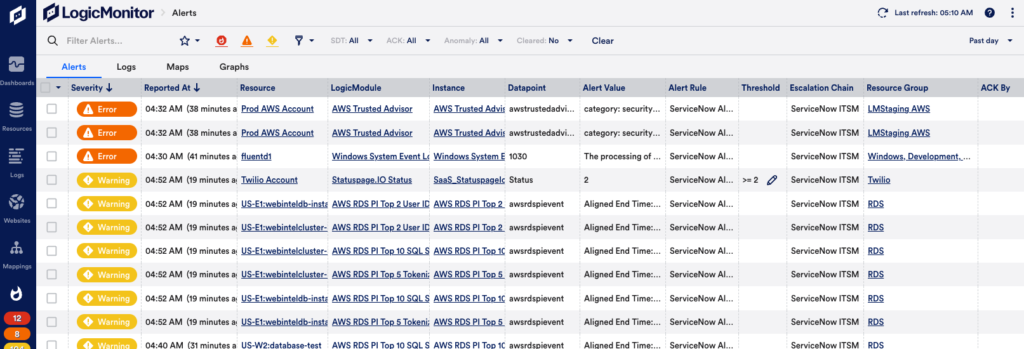
見逃したアラート
最高の監視システムでも、システム障害が検出されないことがあります。 これはいつでも明らかに悪いことですが、監視システムを別の監視システムに交換した後は特にそうです。 ピカピカの新しい SaaS システムがプロダクション ダウン インシデントを見逃したときに、自作の Nagios によって生成された何千もの誤ったアラートを覚えている人は誰もいません。
これが必然的に新しいシステムに導入されるという懐疑論に対抗するには、すべての停止に対して適切な「責任のない」事後分析プラクティスを実施することが不可欠です。 このような事後分析で尋ねる有用な質問のチェックリストには、次のものがあります。
- 失敗の根本原因は何でしたか?
- 障害が発生する前のシステムの状態は?
- 消費された CPU の量、メモリの量は?
- 私たちは交換していましたか?
- トリガーされるべきアラートはありましたか?
- しきい値は適切でしたか?
これには、データ グラフが役立ちます。 通常のシステム使用時のグラフと、システム障害直前のグラフを比較します。 LogicMonitor を使用すると、ビルドすることでこれを行うことができます。 ダッシュボード インフラストラクチャ全体にわたって関連するグラフとメトリックを表示します。 上記のすべてについて議論した後、あなたが答える必要がある次の一連の質問は、将来これを防ぐために私たちができることに関するものです. 再発を防ぐために監視が実施されるまで、問題が解決済みとしてマークされないことが重要です。
電子メールの過負荷の回避
私が働いてきたほとんどの場所では、夜中に呼び出して目を覚ます可能性のある誤ったアラートを防ぐために多大な努力を払っています. ただし、電子メール アラートは別の話であることがよくあります。 一部の企業では、多くの場合自己修正される警告レベルの状況に対して何千もの電子メール アラートを送信することを許可していますが、システム管理者がアラートがクリティカルに達してウェイクアップするのを防ぐための措置を講じることができるディスク使用量の警告など、他の警告が役立つ場合があります。夜中に誰か。 残念ながら、何千もの電子メールを手動でスキャンして、実際に役立つ可能性のあるものを探すのは現実的ではありません。 LogicMonitor などの優れた監視ツールは、アラート ステータスを示すダッシュボードを提供します。
アラート予測
アラート戦略を次のレベルに引き上げたい場合は、アラート予測をミックスに追加する必要があります。 スタンドアロン アラートはメトリックの特定の変化を通知できますが、アラート予測を使用すると、そのメトリックが将来どのように動作するかを予測できます。 また、予測により、メトリックの傾向を予測し、アラートが指定されたアラートしきい値にいつ到達するかを知ることができます。
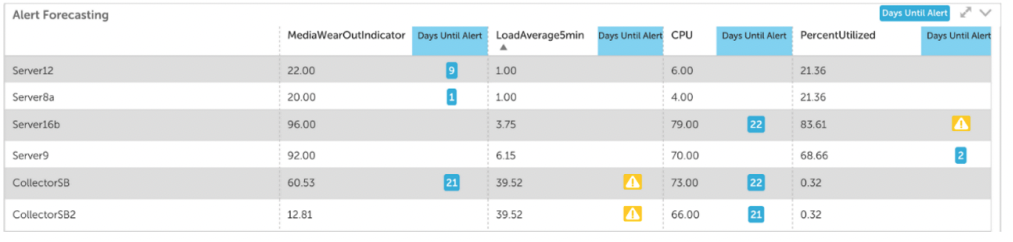
この情報を使用して、パフォーマンスの問題の緊急性に優先順位を付け、予算の予測を改善し、リソースの割り当てを戦略化できます。 アラート予測の有用な例としては、ディスクがいつ 95% の容量になるかを予測したり、毎月の合計を予測したりすることが挙げられます。 AWS 明細書。 LogicMonitor にはアラート予測が含まれており、これを使用して将来の最大 XNUMX か月のアラートを予測できます。
各種レポート作成
適切なレポートは、上記の電子メールの過負荷の状況に役立ちます。 LogicMonitor のトレーニング セッションで得た貴重なアドバイスの XNUMX つは、すべての警告レベルのアラートについて夜間レポートを生成し、アラート配信を無効にすることでした。 その後、管理者は朝のレポートを確認し、警告に対処して、エラーまたは重大なレベルにエスカレートするのを防ぐことができます。
もう XNUMX つの役立つレポートは、すべてのアラートしきい値のレポートです。 これは、現在設定されているしきい値を確認するのに役立ちますが、最も重要なのは、無効になっているしきい値を表示することです。 アラートの過剰なノイズに対する一般的な対応の XNUMX つは、メトリックまたはホスト全体のアラートを無効にすることです。 これは多くの場合、午前中に問題に対処することを意図して行われますが、より優先度の高い人が介入することが多く、警告されていない大惨事が発生するまで忘れられます.

まとめ
最新の監視ソリューションは、必要に応じてアラートを出し、アラートの過負荷を回避できる堅牢なインフラストラクチャ監視フレームワークを提供できます。 ただし、最高のツールであっても、慎重な実装と継続的な調整と改善が必要であることを認識することが重要です。 これは、監視システムを維持する運用担当者だけの責任ではありません。 新しい機能を設計するときは、それらをどのように監視するかを慎重に検討する必要があります。 アプリケーションまたはシステム全体の正常な機能を示す指標は何ですか? 特定のメトリックの許容可能なしきい値は? どの時点で警告を受ける必要があり、警告が重大な状況にエスカレートするのを防ぐために何をすべきか。
今日の Web および SaaS プラットフォームの複雑な性質は、運用チームが運用インフラストラクチャに適用するものとして監視を行うことができないことを意味します。 適切なものを監視し、適切な人に警告していることを確認するには、チーム間のコラボレーションが必要です。 これは、監視戦略を成功させるための鍵です。
LogicMonitorの統合監視プラットフォームは、背後にあるテクノロジーを進歩させることにより、ビジネスの可能性を広げます。 14 日間の無料トライアルにサインアップする.
このホワイトペーパーの無料コピーをご希望ですか?
2022 年 27 月更新。2016 年 2019 月 XNUMX 日に投稿。XNUMX 年も更新。