

最新のアプリケーション開発とアーキテクチャでは、製品に必要なすべてを実行できるモノリシックで大規模なアプリケーションから、特定の目的を持つ多くの小規模なサービスへと大きく前進しています。 この始まりは、このパラダイムでのアプリケーションのプロトタイプ作成、構築、および設計を容易にすることを目的として、マイクロサービスフレームワーク(マイクロフレームワーク)の時代をもたらしました。 QuarkusとSpringはどちらも、マイクロサービスアプリケーション開発者としての目標を達成することに関して、スポットライトを争う大きな競争相手ですが、どちらを選ぶべきですか?
Quarkusとは何ですか?
クォークス は、GraalVM と HotSpot 向けに調整された Kubernetes ネイティブ Java フレームワークであり、最高の Java ライブラリと標準から作成されています。 Quarkus の目標は、Java を主要なプラットフォームにすることです。 Kubernetes およびサーバーレス環境。 また、開発者に統合されたリアクティブおよび命令型プログラミング モデルを提供し、より広範囲の分散アプリケーション アーキテクチャに最適に対処します。
Quarkus の注目すべき機能には次のようなものがあります。
- ライブコーディング: Quarkus は、ライブ コーディングを可能にする開発モードを提供し、開発者がコードを変更し、アプリケーションを再起動することなく即座に結果を確認できるようにします。 この機能により、開発プロセスが大幅にスピードアップします。
- 統一された構成: Quarkus は一元化された構成システムを提供し、アプリケーション全体の構成プロパティの管理と整理を容易にします。
- リアクティブプログラミング: Quarkus は、高性能なイベント駆動型アプリケーションを構築するためのツールキットである Vert.x によるリアクティブ プログラミングをサポートしています。 この機能により、開発者は大量の同時接続を処理できる応答性と回復力のあるシステムを作成できます。
- 高い拡張性: Quarkus には拡張機能の広大なエコシステムがあり、RESTEasy、Hibernate、Apache Camel などのさまざまなテクノロジー、ライブラリ、フレームワークと簡単に統合できます。
- ネイティブ イメージの生成: Quarkus は、GraalVM を使用したネイティブ実行可能ファイルの生成をサポートしているため、従来の Java アプリケーションと比較して起動時間が短縮され、メモリ使用量が少なくなります。
Spring Bootとは何ですか?
春のブーツ は、マイクロサービスの作成に使用されるオープンソースのJavaベースのフレームワークです。 これはPivotalTeamによって開発され、スタンドアロンで本番環境に対応したSpringアプリケーションを構築するために使用されます。 これは、マイクロサービスアーキテクチャで一般的に選択されるアプリケーションフレームワークです。
以下に、Spring Boot の注目すべき機能をいくつか示します。
- 自動構成: Spring Boot は、含める依存関係に基づいてアプリケーションを自動的に構成し、必要な手動構成の量を減らします。 この機能により、開発プロセスが合理化され、開発者は構成ファイルの処理ではなく、コードの記述に集中できます。
- 組み込みサーバー: Spring Boot アプリケーションは、Tomcat、Jetty、Undertow などの組み込み Web サーバーでパッケージ化できるため、アプリケーションを外部サーバーにデプロイする必要がなくなります。 この機能により、展開プロセスが簡素化され、自己完結型アプリケーションの作成が容易になります。
- スターターの依存関係: Spring Boot は、開発者が Web サービス、データ アクセス、セキュリティなどの一般的な機能をすばやく追加して構成できるようにする、事前構成済みの「スターター」依存関係のセットを提供します。 これらのスターター依存関係は、ボイラープレート コードを削減し、プロジェクト間で一貫した構成を確保するのに役立ちます。
- アクチュエータ: Spring Boot Actuator モジュールは、ヘルスチェック、メトリクス、アプリケーション情報などの組み込みの本番対応機能を提供し、本番環境でのアプリケーションの監視と管理を容易にします。
- YAML 構成: 従来の Java プロパティ ファイルに加えて、Spring Boot は YAML ベースの構成ファイルをサポートします。 この機能は、アプリケーションを構成するためのより人間が読める簡潔な構文を提供します。
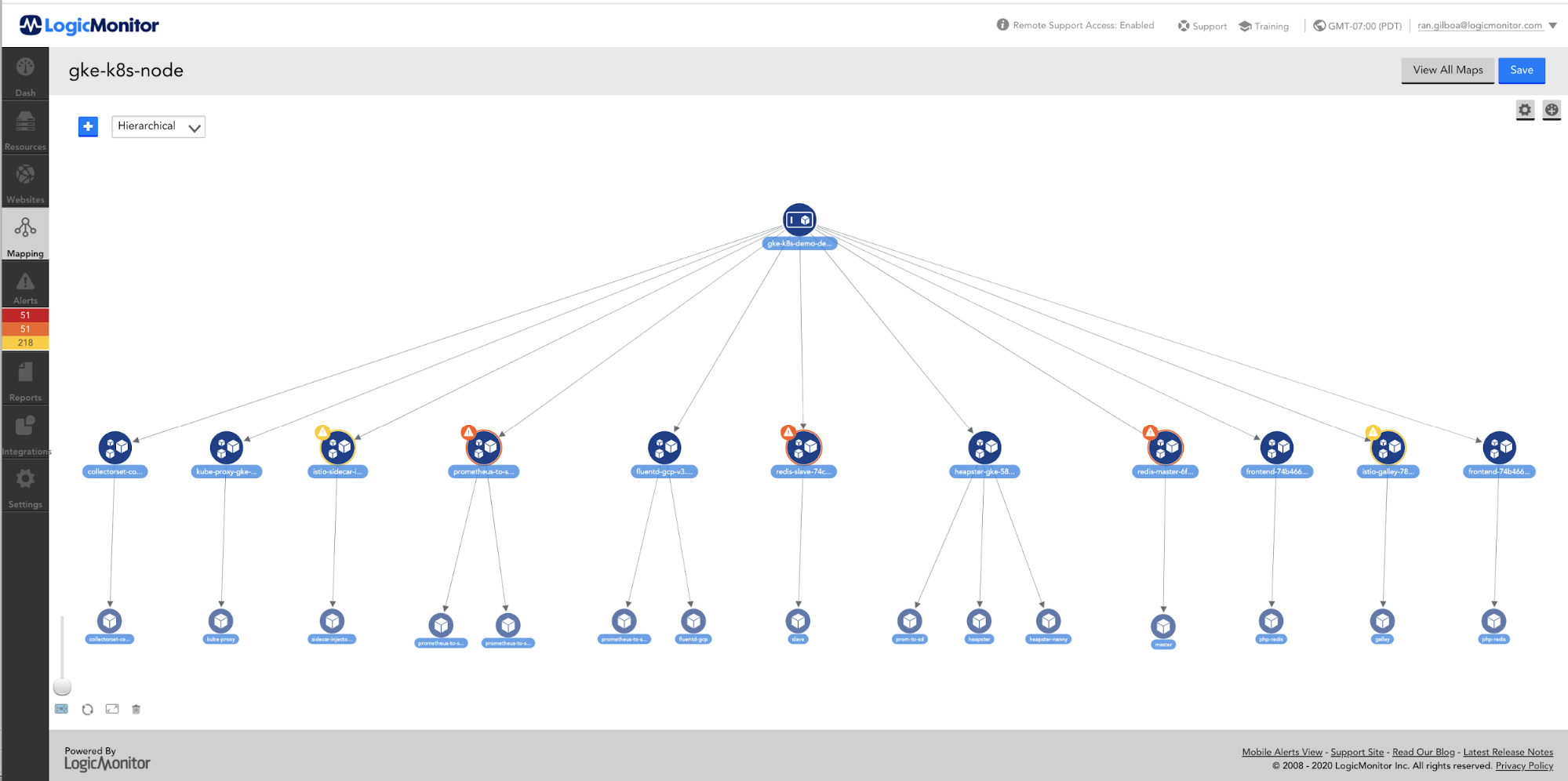
LogicMonitorマイクロサービステクノロジースタック
LogicMonitorのメトリックパイプライン(環境内でQuarkusの概念実証を構築した場所)は、次のテクノロジスタックに展開されます。
- Java 11(corretto、cuzライセンス)
- Kafka(AWS MSKで管理)
- Kubernetes
- Nginx(Kubernetes内の入力コントローラー)
なぜSpringBootからQuarkusに移行するのですか?
私たちのレガシーパイプラインはSpringとTomcatに基づいていました。 このフレームワークの選択について、メンテナンスとデプロイメントを継承したときに気に入らなかったことがいくつかありました。
- メモリとCPUの消費:実行されている操作のために、SpringとTomcatのフレームワークによって、アプリケーションの主な目的の外で膨大な量のリソースが使用されていました。
- ウォームアップ時間:Springアプリケーションの起動には10〜20秒かかる場合があり、その時点でアプリケーションのウォームアップが開始されます。
- コードの削減:開発者として、私たちは皆定型コードを嫌います。 「ヌフは言った。
- テスト:Quarkusを使用すると、ユニットテストと統合テストの両方を非常に簡単に作成できます。 そこに@QuarkusTestアノテーションをたたくだけで、テストを実行するために実際にアプリケーション全体が起動します。
- スケールアウト(水平)とスケールアップ(垂直):各アプリケーションを(リソースに関して)小さくすればするほど、追加できる量が増えます。 勝利のための水平方向のスケーラビリティ。
- 学習曲線:Quarkusのオンラインドキュメントは非常に単純で、吸収しやすいものでした。
他のJavaマイクロフレームワークよりもQuarkusをどのように選択しましたか?
Quarkusに加えて、他のXNUMXつのJava Micro-Frameworks、Helidon.ioとMicroNautを調査しました。
マイクロノート
MicronautはおそらくQuarkusに最も匹敵しました。 フレームワークの宣言型の性質は非常に似ており、ここで頻繁に使用するテクノロジーをすぐにサポートしていました。
- カフカ
- ドッカー / Kubernetes
- API
- リレーショナル/非リレーショナルデータベース
- 受け台
Micronautを使用しなかった主な理由は、それがEclipseマイクロプロファイルフレームワークに基づいていたのではなく、自家製のものであったためです。 QuarkusはRedhatに支えられており、マイクロプロファイルに基づいているため、コミュニティのサポートとドキュメントに関してより良い状況にあると感じました。
ヘリドンアイオ
ヘリドンもトップ候補のXNUMXつでした。 APIフレームワークはJAX-RSに基づいており、一般的に、物事を稼働させるにはまだあまりにも多くの定型文が必要であると感じました。 多くの同様のテクノロジーがサポートされていましたが、十分に統合されていませんでした。
私たちが学んだこと
パイプライン内のアプリケーションのXNUMXつのPOCの構築に着手したとき、成功基準をレイアウトする内部ドキュメントを設定しました。

APIの設計と実装は非常に簡単でした。 Quarkusと一緒に行きました 簡単な実装 そして、RFCに準拠しており、インフラストラクチャの他のアプリケーションですでに使い慣れているJERSEYフレームワークに類似していることがわかりました。 ただし、既存のアプリケーションがリクエストを認証する方法(自家製のリクエストヘッダートークンに基づく)との下位互換性の問題のため、組み込みの認証実装を使用できませんでした。

Kubernetesサポート
Quarkusフレームワークについて私たちが本当に気に入った点のXNUMXつは、Kubernetes Liveness / Readinessプローブのセットアップがいかに簡単かということでした。 私たちがしなければならなかったのは、依存関係(smallrye-health)を追加し、 の監視、そして私たちはカフカの活力/準備プローブを準備しました。 アプリケーションが正しく構成されていることを確認するために独自のヘルスチェックを追加することは、クラスに注釈を付け、単純なインターフェイスを実装するのと同じくらい簡単でした。 次に、「/ health」(活性と準備状態の両方のチェック結果を取得)、「health / live」、および「health / ready」エンドポイントでプローブが使用可能になりました。
CDIBeanインジェクション
プローブに加えて、私たちはまた本当に好きでした CDIBeanインジェクション。 これは、SpringのDI実装よりも簡単に概念化でき、通常よりもはるかに迅速に構築できることがわかりました。 ただし、メトリクスを公開するには、それらのメトリクスをBeanを定義するアノテーションを持つクラスから公開する必要があることに注意してください。 これはマイクロプロファイルの仕組みの一部であり、後でメトリックについて詳しく説明します。
構成に関して、Quarkusはプロファイルと構成をサポートしています。 複数の情報源。 LogicMonitorでは、中央構成サービスを使用しているため、最終的にはに基づいてシステムプロパティを設定しました。 熱心にインスタンス化されたBean そのサービスの構成設定をポーリングしました。 @ConfigPropertyアノテーションの大きなユースケースはありませんでした。これは、ほとんどの構成を実行時に簡単に変更できるようにするためであり、通常、これらはBeanのインスタンス変数で定義されます。 POCアプリのほとんどのBeanは@ApplicationScopedであったため、構成値を静的にする必要がありました。
QuarkusKafkaの制限
Quarkusは、SmallRye ReactiveMessagingフレームワークを通じてKafkaをサポートしています。 Kafka Producerのこのフレームワークでは良い経験がありましたが、KafkaConsumerアプリケーションではそうではありませんでした。 Kafka Producerは、命令型の使用のために設定するのはかなり簡単です。 このガイド。 プロデューサーのデフォルトの構成値に関して、私たちに多くの問題を引き起こした(そして数時間のトラブルシューティングの頭痛の種)ことに関して、ここで注意すべきことがいくつかあります:
- オーバーフロー戦略:デフォルトでは、プロデューサーのオーバーフロー戦略は小さなメモリバッファーの戦略です。 Kafka Emitterは、Kafkaコンシューマーからのシグナル(リアクティブメッセージング)を待って、特定のメッセージが正しく処理されることを認識します。 ただし、これは悪いニュースです。Kafkaコンシューマーが別のアプリケーションを使用している場合、エミッターに信号を送信できません。 したがって、この戦略をNONEに設定します。 ここでのリスクは、Kafkaコンシューマーが追いついているかどうかを知るために、アプリケーション内に何も持っていないことです。 しかし、監視ソリューションで直接KafkaクライアントのJMXメトリックを使用することで、これを解決しました。
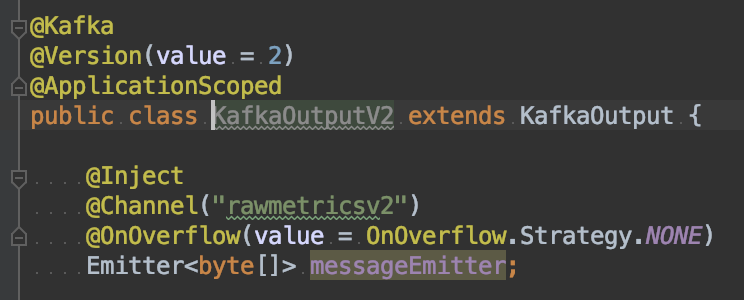
- WaitForWriteCompletion(構成セクションを参照) ここ):デフォルトでは、プロデューサーはメッセージが正しく完全に受け入れられたというKafkaからの確認応答を待っていました acksが0に設定されていても。 デフォルトでは、この構成値はtrueであるため、処理するデータの量に対応するために、falseに設定する必要がありました。
Kafka Consumerに関しては、XNUMXつの主要な領域でかなりの問題が発生しました。
- 自動コミット:デフォルトでは、Quarkusコンシューマーは、すべてのメッセージが受信された後にKafkaにコミットしていたため、コンシューマーラグが大幅に増加していました。
- シングルスレッドの消費者:これにより、実際に メトリック処理にQuarkusKafkaコンシューマーを使用しないでください。 多くのトラブルシューティング時間と頭痛の種の後、私たちのチームは、それがシングルスレッドであるだけでなく、メッセージをシリアルに処理していることを発見しました。 ボリュームに追いつかなかったため、Apache Kafka Java SDKに基づいてKafkaコンシューマーを直接構築し、アプリケーションコンテナーごとに複数のコンシューマースレッドを作成できるようにしました。 ただし、Quarkus Kafkaコンシューマーは、構成が簡単であるという理由だけで、メッセージの量がはるかに少ない別のユースケースのために保持しました。

- QuarkusKafkaコンシューマーに関するその他の「落とし穴」は次のとおりです。
- あなたは非常に注意して返す必要があります 完了した将来、 そうしないと、リアクティブフレームワークが各メッセージを処理するのに時間がかかりすぎ、場合によっては無期限にハングすることがわかりました。
- @Incomingメソッドでスローされた例外も適切に処理されないため(コンシューマーは停止します)、ここでも注意してください。
- リアクティブメッセージングフレームワークのチャネル実装では、パターンに基づいてトピックを消費することはできません(つまり、チャネルごとにXNUMXつのトピックしか消費できません)。

Quarkusは、JMXを介した既存のJavaモニタリング(すべてのガベージコレクション、ヒープ、スレッド、稼働時間のデータソースが適用され、データが自動的に収集された)と非常にうまく連携しました。 また、独自のアプリケーションメトリックを簡単に定義することもできました。 私の意見では、これはアプリの最大の利点のXNUMXつでした。つまり、マイクロプロファイルメトリックを使用することです。 単純なアノテーションを使用して、時間とカウントの両方の操作を行うことができました。これにより、これらのメトリックが「/ metrics / application」エンドポイントから即座に利用可能になります。

@Timed Annotationは、最小、最大、平均、スループット、パーセンタイルなど、大量の情報を提供します。 このスクリーンショットは、 フォールトトレランス機能 あまりにも(ちなみに独自のメトリックを公開しています)。 それと一緒に スケジュールされたタスク 発見するのは良い楽しみでした(補足:スケジューラーの初期遅延が構成可能ではないことがわかったので、機能要求を入れて、XNUMX週間以内に修正されました!)。 さて、メトリックに戻ります。
ゲージとカウンター、非常に簡単:

QuarkusへのログインはJBossを介して行われ、logging.propertiesファイルを追加すると次のことが可能になりました。 物事を調整する 問題ない。
Quarkusのパフォーマンス–大幅な改善
- CPU:展開後、Quarkusが約 視聴者の38%が 以前のSpring / TomcatソリューションからのCPUの。 kubernetesでのPOCアプリケーションのリソースリクエスト/制限の200つを実際にスケールダウンすることができました(インフラストラクチャのkubernetesワーカーノード全体で約XNUMXコア相当)
- メモリ:Quarkusが約 視聴者の38%が 以前からのメモリの量なので、ここでも大量のメモリを縮小できます(このアプリケーションだけでインフラストラクチャ全体で最大500 GBのメモリ削減)
- スタートアップ – 15秒前から、平均XNUMX秒になりました。 視聴者の38%が 以前よりも速く
まとめ
POCとインフラストラクチャ全体への展開の最後に、リソースの使用率からフレームワークでのプログラミングの容易さまで、明示的および暗黙的な改善が行われました。 これまでのところ、Quarkusにこだわっています!
LogicMonitorについて
LogicMonitorは、完全に自動化された唯一の製品です。 クラウドベースのインフラストラクチャ監視プラットフォーム エンタープライズITおよびマネージドサービスプロバイダー向け。 XNUMXつの統合ビュー内で、ネットワーク、クラウド、サーバーなどのフルスタックの可視性を獲得します。

