

LogicMonitor では、時系列メトリック データの取り込みと処理は、統合された可観測性プラットフォームの最も重要な部分であることに間違いありません。 成長、規模、フォールト トレランスに完全に備えるために、メトリクス処理パイプラインと呼ばれるものをモノリスからマイクロサービス主導のアーキテクチャに進化させました。 以前、一連の記事で私たちの進化の旅について詳しく説明しました。
しかし、モノリス システムから分散型マイクロサービスおよびメッセージ駆動型アーキテクチャへの進化を進めるにつれて、新たな問題が発生しました。 この記事では、そのような問題の XNUMX つと、ソリューションをどのように設計したかについて詳しく説明します。
Kafka ベースのマイクロサービス アーキテクチャとスケーリングの課題
Quarkus と Kubernetes を使用して Kafka から消費する
まず、高レベルの部分的なアーキテクチャの概要を考えてみましょう。 時系列メトリック データを取り込んだ後、データは最終的に Kafka トピックに送られ、そこでマイクロサービスによって消費および処理されます。 これは Kubernetes で実行され、 クォークス フレームワーク。 このマイクロサービスの複数のインスタンスを実行し、それらは同じインスタンスに参加します カフカ消費者グループ. Kafka トピックのパーティションはグループ内のコンシューマーに割り当てられ、サービスがスケールアウトすると、より多くのインスタンスが作成されてコンシューマー グループに参加します。 パーティションの割り当てはコンシューマー間で再調整され、各インスタンスは XNUMX つ以上のパーティションを取得して作業します。
このマイクロサービスは計算集約型のアプリケーションであり、 Kubernetes 水平ポッド オートスケーラー (HPA) CPU 使用率メトリックに基づいてアプリケーションのインスタンスを自動的にスケーリングします。
LogicMonitor では、複数の異なる データポイント メトリック タイプ 取り込んだ時系列データの場合。 ソースからデータを収集した後、メトリック タイプによって決定されるデータポイントの実際の値を生成するために、生データをさらに処理する必要があります。 この処理の要件として、Kafka からの着信メッセージを処理するときに、データポイントごとに以前の既存のデータをキャッシュする必要があります。 このように Kafka を使用する方法の詳細については、こちらをご覧ください。 この記事.
ステートフル Kubernetes マイクロサービスのスケーリングの課題
ここで、問題の核心に到達します。 スケーラビリティとスループットを最大化するために、計算負荷に基づいてスケールインおよびスケールアウトする、複数インスタンスのメッセージを消費するアプリケーションを構築しました。 さらに、Kafka コンシューマー グループのメンバーシップは本質的に非常に動的であり、さまざまなパーティションが同じグループ内の XNUMX つのコンシューマーから別のコンシューマーに移動する可能性があります。
ただし、前述したように、処理する各データポイントには、それに関連付けられた状態 (キャッシュされた既存のデータ) があります。 したがって、スケールダウン イベントが原因で Kubernetes ポッドが強制終了されることは、損失のないインシデントではありません。 これで、このポッドが処理していたデータ ポイントに関連付けられたコンテキストが失われます。 同様に、Kafka パーティションの再割り当てもロスレス インシデントではありません。 パーティションを取得する新しいコンシューマーは、パーティション内のデータ ポイントのコンテキストを持っていないか、古い古いコンテキストを持っています。
このコンテキストの喪失が発生するたびに、メトリクス処理で一時的な不一致が発生します。 Kubernetes ポッドのシャットダウンまたは Kafka パーティションの再割り当てによって発生する、このコンテキストの喪失に対処する必要があります。
分散キャッシュを選択する際のコスト パフォーマンスに関する考慮事項
一見したところ、これには明らかな解決策があるように見えます。コンテキストを保存するために使用してきたインメモリ キャッシュを、何らかの分散キャッシュに置き換えます。 ただし、そのソリューションをより複雑にする他の要因があります。
- 速度 – LogicMonitor が取り込むデータ量が非常に多いため、メトリクス処理パイプラインは速度に依存しています。 生のメトリクス メッセージの評価ごとに分散キャッシュを導入すると、非常に安価なインメモリ ルックアップを、ネットワークを介した外部システムへのルックアップに置き換えることになります。 このようなルックアップがパイプラインの速度に悪影響を与える可能性は高くなります。
- 費用 - 大量のメッセージが処理されるため、メッセージごとに分散キャッシュを呼び出すと、多大なコストが発生します。 たとえば、キャッシュには、このような頻繁なトラフィックを処理するのに十分なリソース割り当てが必要であり、追加で必要なネットワーク帯域幅もコストに影響します。
- キャッシュされるデータの性質 – データポイントに関連付けられたコンテキストを保存するために、メトリクス処理専用の社内データ構造を構築しました。 さまざまなキャッシング システムを最初に調査したところ、直接的な代替手段を提供するものはなく、外部キャッシュに保存するためにデータをマッサージ/変更する必要があることがわかりました。 ただし、書き込み/読み取りのたびにデータをシリアライズ/デシリアライズする必要がある場合、全体の処理速度は低下します。
Redis を使用してスケーラブルなマイクロサービスの状態を保持する
分散キャッシュとインメモリ キャッシュの間で状態ストレージのバランスを取る
自然な解決策は、メモリ内キャッシュと外部分散キャッシュの中間点です。 コンテキスト データをメモリに保存し続けます。 このデータの損失を引き起こす XNUMX つのシナリオがあります。
- コンテナーが Kubernetes によってシャットダウンされた (スケールダウン イベントまたはデプロイのため)
- Kafka コンシューマー グループでパーティションのリバランスがトリガーされる
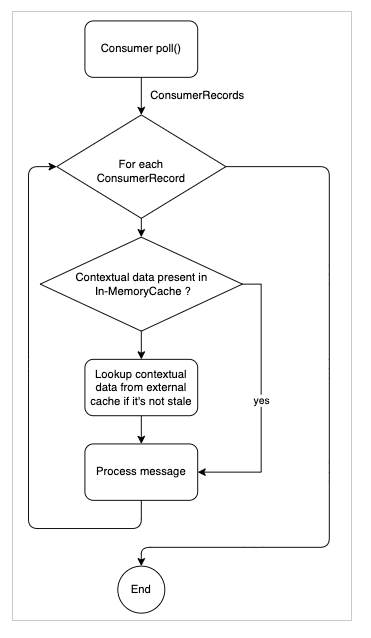
これら XNUMX つのイベントがいつ発生したかを検出し、外部分散キャッシュへのコンテキスト データの永続化をトリガーできれば、「状態」を保存できるはずです。 その後、コンテキスト データを検索しているときに、メモリ内キャッシュに存在しない場合は外部キャッシュから検索し、見つかった場合はメモリ内キャッシュに挿入して復元します。状態。"
コンテナのシャットダウンとパーティションのリバランス中にコンテキスト データを外部の分散永続キャッシュに保存することで、オーバーヘッドをあまり発生させずにコンテキストを失うことができ、コンテキスト データの損失を回避できます。 コンテキスト データを外部キャッシュから検索するだけで (インメモリ キャッシュに見つからない場合)、オーバーヘッドが過度に増加することを回避できます。
AWS ElastiCache Redis を選んだ理由
クラスターモードを選択しました AWS ElastiCache Redis 分散キャッシュとして。 主な理由のいくつかを次に示します。
- XNUMX つの特定のデータソース インスタンスのコンテキスト データをすばやく検索する必要があります。 したがって、次のようなキー値ベースのデータストア Redisの 理想的です。
- Redis の書き込み時間とアクセス時間は非常に優れており、コンテキスト データをすばやくダンプして読み戻すことができるという要件を満たしています。
- バックアップしているコンテキスト データに回復力があることを望んでいます。 Redis 用 AWS ElasticCache クラスターモードでは、データを複数のシャードに分散し、レプリケーションも提供することで、私たちが求めている柔軟性を提供します
- LogicMonitor プラットフォームが成長するにつれて、水平方向にスケーリングできる分散キャッシングを使用したいと考えています。 AWS ElastiCache Redis は、Redis クラスターに中断のない水平スケーリングを提供します。
Quarkus シャットダウン フック、Kafka リスナー、および Redisson の活用
ソリューションの実装方法は次のとおりです。
- 私たちは、使用しました レディソン Redisとして クライアント
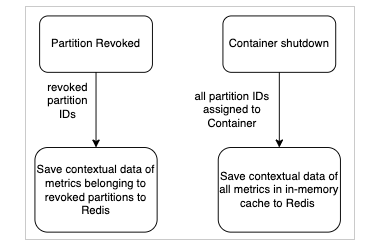
- Quarkus フレームワークの シャットダウンフック Kubernetes コンテナーのシャットダウンをリッスンし、コンテキスト データのバックアップをトリガーする
- 私たちは、使用しました Kafka ConsumerRebalanceListener Kafka コンシューマー リバランス イベントをリッスンし、イベントで取り消されたパーティションのコンテキスト データのバックアップをトリガーする
- メモリ内にキャッシュされたデータをRedisにすばやく書き込み、Redisからバックアップされたデータをすばやく読み取ることを目的とした、独自の社内シリアライゼーションおよびデシリアライゼーションロジックを実装しました
- データのバックアップを高速化するために、プロセスを並列化しました
- Redis から永続化されたデータを読み戻すときに、Redis から古い情報を読み取っていないことを確認するチェックを実装しました。 データがこのチェックに合格しなかった場合、そのデータは破棄されました。
圧縮と TTL を使用して Redis メモリ使用量を最適化する
- Redis クラスターのメモリ要件とネットワーク I/O を最小限に抑えるために、 lz4 Redis に保存する前にコンテキスト データを圧縮するための圧縮アルゴリズム。 もう一方の端では、Redisson の圧縮機能を使用して、フェッチ後にデータを同時に解凍します。
- コンテキスト データは、関連する LogicMonitor データソースの次の数回のポーリング間隔にのみ関連するため、Redis に保存するコンテキスト データは長期間 Redis にとどまる必要はありません。 Redis クラスターのメモリ使用量をさらに最適化するために、関連する LM データソースの収集間隔に基づいて、Redis に保存する各コンテキスト データの TTL (time-to-live) 値を設定します。 これにより、データが不要になったときに Redis メモリを自動的に解放できます。
- コンテキスト データを Redis にバックアップしたら、ローカルのメモリ内キャッシュからデータを無効にして削除します。 これには次の利点があります。
- コンテキスト データが Redis にバックアップされると、それ以降はバックアップされなくなります。 これにより、最新のコンテキスト データのみが Redis に存在することも保証されます
- アプリ内キャッシュに、不要な潜在的なコンテキスト データが含まれないようにする
- アプリ内メモリを解放します
まとめ
LogicMonitor は引き続きモノリシック サービスをマイクロサービスに移行し、サービスの開発、展開、および保守方法を改善します。 旅行中の私たちの経験に関する他の記事をチェックしてください。

