アマゾンウェブサービスエラスティックロードバランサー(AWS ELB)を使用すると、必要に応じてサーバーを追加することで、ウェブサイトやウェブサービスがユーザーからのリクエストをさらに処理できるようになります。 ELBが異常な場合、Webサイトがオフラインになったり、大幅に遅くなったりする可能性があります。
この記事では、以下について説明します。
- 利用可能なメトリック
- より意味のある計算されたメトリックを追加する方法
- 主要な指標は?
- 異常検出を使用するメトリック
ELB(Elastic Load Balancer)とは何ですか?
弾性負荷分散 着信アプリケーショントラフィックを複数のAmazonEC2インスタンスに自動的に分散します。 これにより、アプリケーションのフォールトトレランスを実現し、アプリケーショントラフィックのルーティングに必要な量の負荷分散容量をシームレスに提供できます。
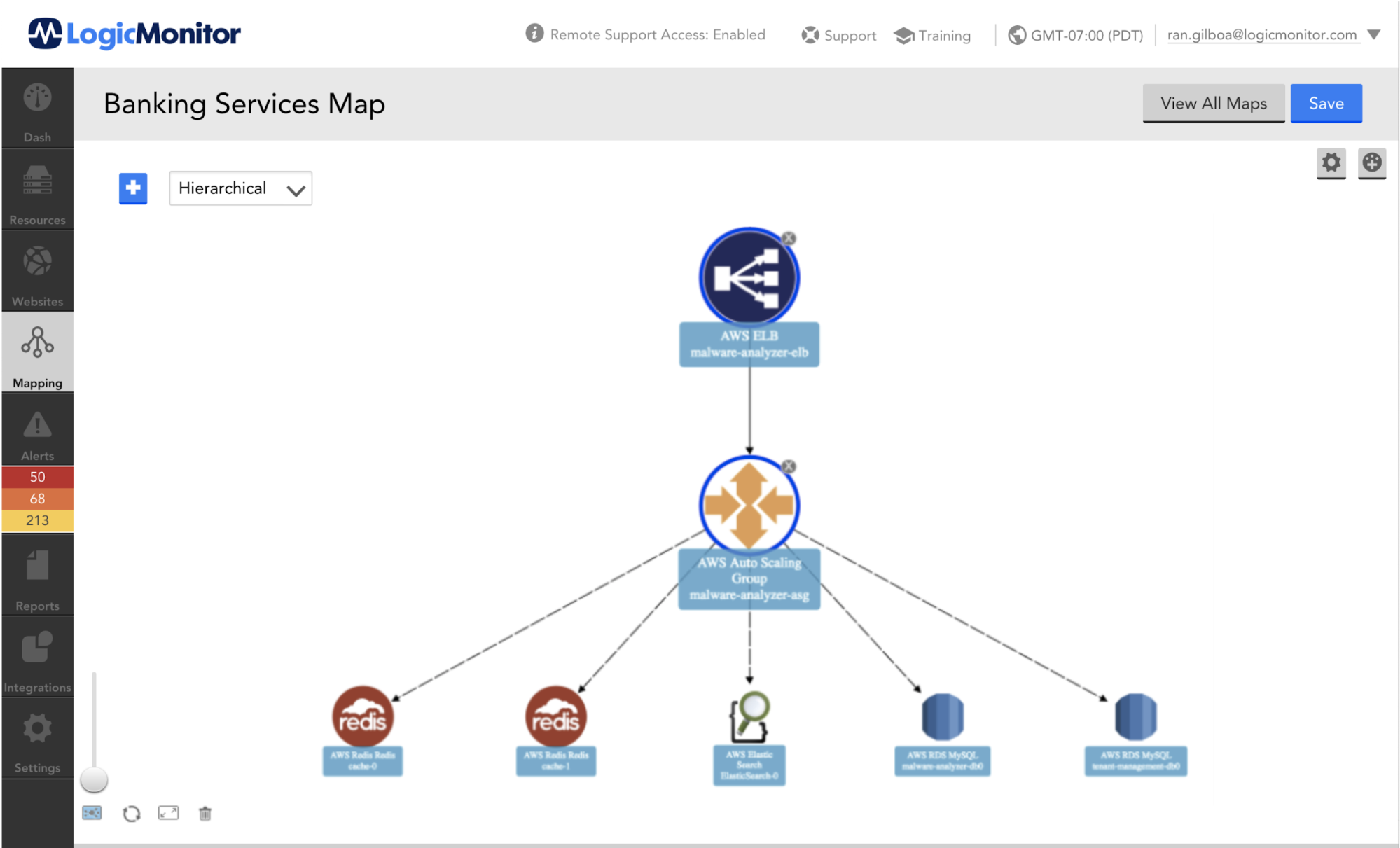
AWSCloudwatchメトリクス
Elastic Load Balancingは、データポイントをに公開します アマゾンクラウドウォッチ ロードバランサーとバックエンドインスタンス用。 CloudWatchを使用すると、これらのデータポイントに関する統計を、メトリクスと呼ばれる時系列データの順序付けられたセットとして取得できます。
なぜ独自のメトリックを追加する必要があるのですか?
見てみましょう 不健全なホスト数、UnHealthyHostCountは、異常と見なされるターゲットEC2インスタンスの数です。 それ自体では、多くを語っていません。 次の質問を検討してください:の値は2ですか 不健全なホスト数 メトリックは良いか悪いか? そして、それはどれくらい良い(または悪い)ですか?
通常、私がこの質問を提示すると、その人は「ELBが持っているEC2インスタンスの数によって異なります」と言うでしょう。
シナリオ1
- ELBによって管理されるEC2インスタンスの数:2
- ELBステータス: 致命的な、ELBは動作不能であり、EC100の2%が異常です。
- 優先順位付け:問題は重大であり、今すぐ修正する必要があります。 私たちはお金を失っています!
シナリオ2
- ELBによって管理されるEC2インスタンスの数:4
- ELBステータス: エラー、ELBは負荷をサポートしていない可能性があり、EC50の2%が異常です。
- 優先順位付け:通常の優先順位付けプロセスに従って問題に対処します。
シナリオ3
- ELBによって管理されるEC2インスタンスの数:20
- ELBステータス: 警告、大きな懸念ではありませんが、EC10の2%が不健康です。
- 優先順位付け:問題は軽微です。 最終的には自然に消える可能性がありますが、エスカレートしていないことを確認するために注意してください。
異常なホスト数などのメトリックにアラートを配置しようとしても、あまり役に立たないことに注意することが重要です。 現在機能する数を選択した場合でも、ELBがサービスを提供している(または単にAuto-Scaling-Groupを使用している)クラスターのサイズを変更して、アラートを役に立たなくする可能性があります。
LogicMonitorが導入されました 複雑なデータポイント
不健全なホストレート= UnHealthyHostCount /(HealthyHostCount + UnHealthyHostCount)
主要な指標は何ですか?
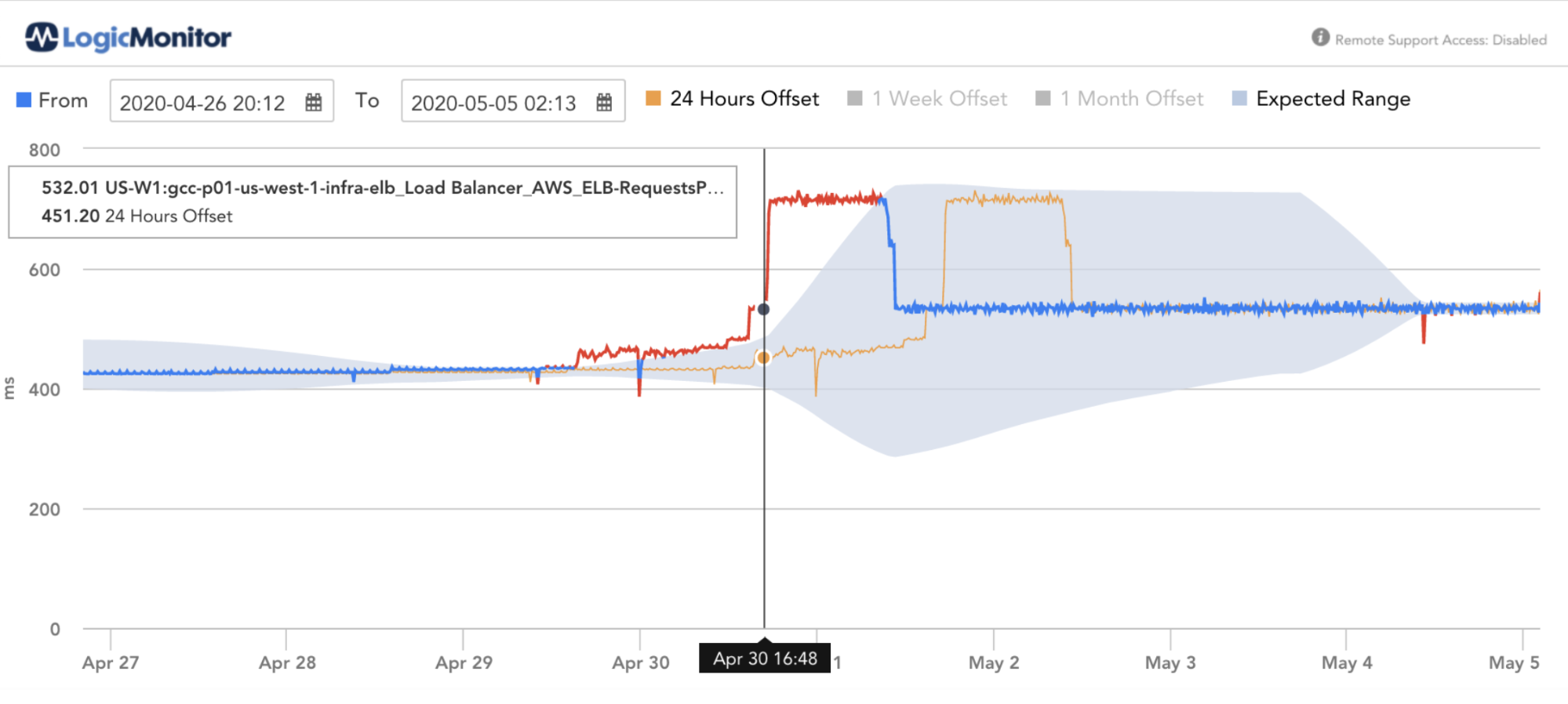
UnHealthyHostRate(複雑なデータポイント)
複雑なデータポイント。正常でないホストの割合を計算します。50%を超える正常なホストは重要と見なされます。
不健全なホストレート= UnHealthyHostCount /(HealthyHostCount + UnHealthyHostCount)
HTTPCode_Backend_5XXRate_Rate(複雑なデータポイント)
複雑なデータポイント。リクエスト全体から5xxエラーの割合を計算します。
HTTPCode_Backend_5XXRate_Rate = HTTPCode_Backend_5XX / RequestCount
HTTPコード_バックエンド_4XXRate_Rate (複雑なデータポイント)
複雑なデータポイント。リクエスト全体から4xxエラーの割合を計算します。
HTTPCode_Backend_5XXRate_Rate = HTTPCode_Backend_5XX / RequestCoun
サージキューレート (複雑なデータポイント)
複雑なデータポイントは、に基づいてキューの%を計算します サージキューの長さ メトリック. サージキューの長さ 正常なインスタンスへのルーティングを保留している要求(HTTPリスナー)または接続(TCPリスナー)の総数です。 キューの最大サイズは1,024です。 キューがいっぱいになると、追加の要求または接続は拒否されます。 詳細については、を参照してください。 スピルオーバー数.
サージキューレート= サージキューの長さ / 1024
スピルオーバー数
サージキューがいっぱいであるために拒否されたリクエストの総数。
[HTTPリスナー]ロードバランサーがHTTP503エラーコードを返します。
[TCPリスナー]ロードバランサーが接続を閉じます。
バックエンド接続エラー
ロードバランサーと登録済みインスタンスの間で正常に確立されなかった接続の数。 ロードバランサーはエラーが発生したときに接続を再試行するため、このカウントは要求レートを超える可能性があります。 このカウントには、ヘルスチェックに関連する接続エラーも含まれることに注意してください。
何をオンにして異常検出を有効にすべきですか?
主要なメトリックに異常検出と静的しきい値を使用することが期待されていますが、他のユースケースもあります。
例
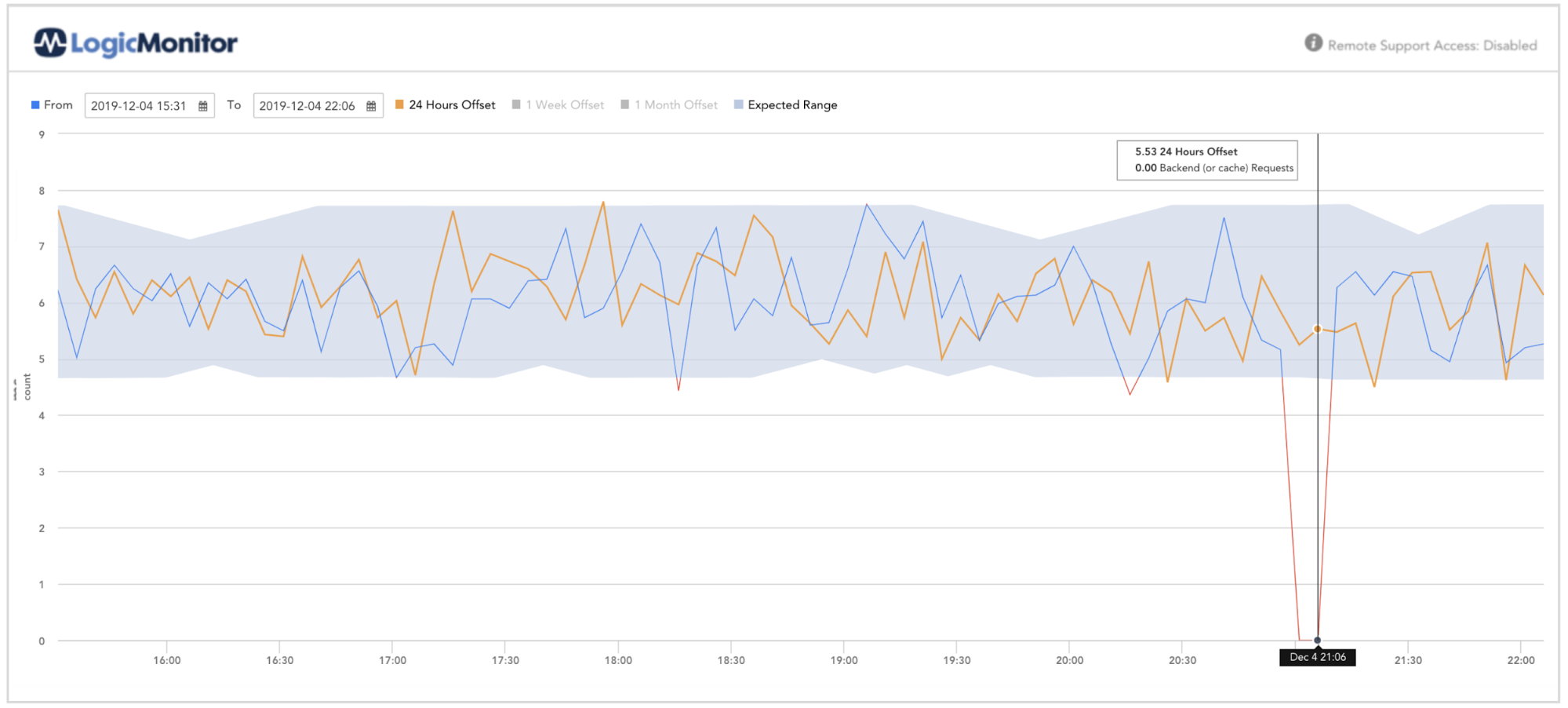
XNUMX秒あたりのリクエスト数の異常検出を有効にすると、予期しない負荷を特定できます。この予期しない負荷は、AWS ELBのサービス拒否攻撃の結果である可能性があります(詳細 AWS(DDoS)攻撃).
例
リクエストがゼロに低下した場合、リモートエラー(rg IOTデバイスが信号の収集を停止)を示している可能性があります。