
LogicMonitorでは、100日あたり約XNUMX億の指標、つまりXNUMX秒あたりXNUMX万を超える指標を保存しています。 その結果、一部のストレージエンジンは、大量のディスクIOを処理する必要があるため、 SSD。 従来、これらはIntelのエンタープライズSSD SATAドライブでしたが、最近ではPCIeSSDに移行しています。 どちらが問題を提起しますか?なぜシステムをPCIe SSDにアップグレードしているのですか? それが必要であるとどうやって知りましたか?
として SaaSベースのパフォーマンス監視 プラットフォームでは、ドライブとシステムに関する多くのデータを収集できます。 しかし、私たちはSSDから取得できるデータと同じくらい優れているだけであり、そのデータは必ずしも私たちが望むほど包括的であるとは限りません。
従来のハードディスクでは、デバイスの使用率(デバイスがアイドル状態ではない時間の割合、つまりビジー)が容量の良い指標です。 グラフにディスクが90%の時間ビジーであることが示されている場合は、リクエストの待ち時間が長くなるため、ドライブをアップグレードするか、スピンドルを追加するか、ワークロードを移動します。 ただし、SSDの場合、 iostatのマニュアルページ 言います:
「... RAIDアレイや最新のSSDなど、リクエストを並行して処理するデバイスの場合、この数値はパフォーマンスの制限を反映していません。」
これは、SSDが同時に複数のリクエストを処理できるためです。多くの場合、SSDは、レイテンシに大きな変化をもたらすことなく、一度に最大64(またはそれ以上)のリクエストを処理するように最適化されています。 デバイスが 利用された 同時により多くの作業を実行できないことを意味するわけではありません。使用されるということは、最大容量を意味するわけではありません。 少なくとも理論的には…
ただし、ワークロードについては、デバイスの使用率が is SSDパフォーマンス容量の優れた予測子。 たとえば、次のグラフを見てください。
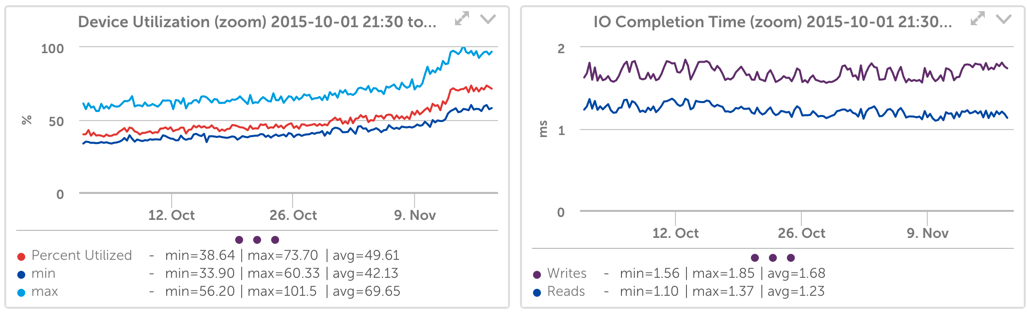
ドライブがビジーである時間(デバイス使用率)が増加すると、書き込み要求の待ち時間も増加したことがわかります。
IO完了時間グラフ(キューイング時間を含む操作が完了するまでの時間を示します)を次のように変更することで、これをわかりやすくすることができます。 ゼロからスケールし、 読み取りを含める:
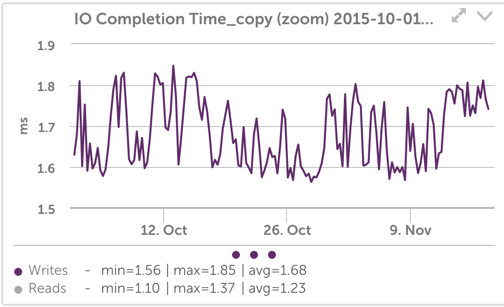
これで、デバイスがビジー状態のときに、書き込みレイテンシが平均で約1.7ミリ秒から持続値である約1.8ミリ秒になったことはもう少し明らかです。 これは小さな変更のように見えますが、レイテンシーが約6%増加しています。
以下に示すように、ディスク操作の数の絶対的な変化はわずかです。
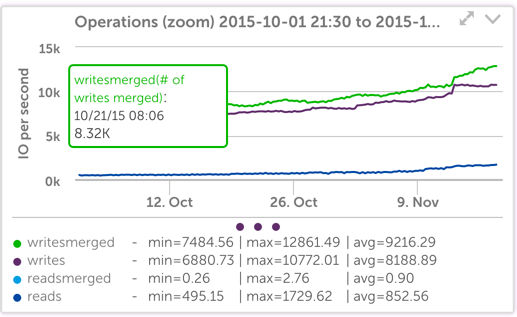
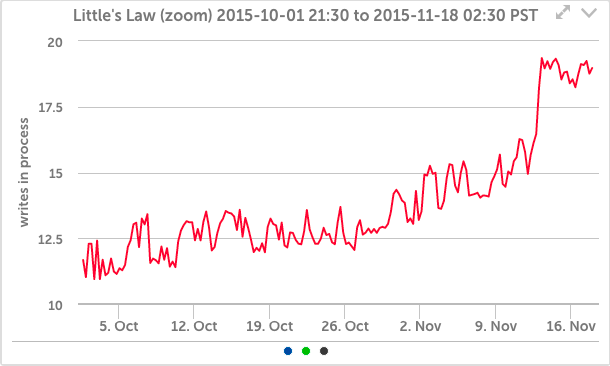
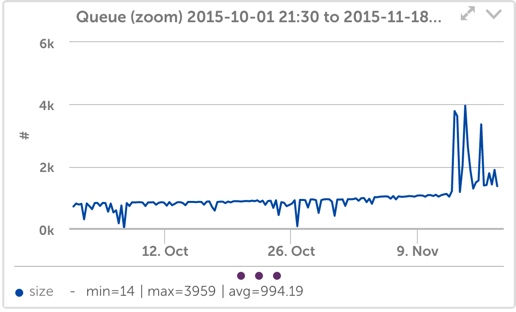
それでも、ファイル操作の数のわずかな変化でさえ、待ち時間の小さな変化と組み合わされると、SSDシステムでキューに入れられるかアクティブになる操作の数に大きな変化が生じることは明らかです(これは リトルの法則 –キュー内または処理中のオブジェクトの数は、到着率に処理時間を掛けたものに等しくなります):
そして私たちのアプリケーションでは、それは内部でキューイングを増やすのに十分です。
この種の不規則なキューイングは、システムの過負荷を示しており、IOシステムが追いつくことができず、キューが大きくなることを意味します。修正しないままにすると、システムは受信データに遅れをとることになります。 それは私たちの運用チームが深夜に呼び出されることになるので、それは私たちが事前に対処しようとしていることです。
この場合、より多くのシステムに負荷を分散することができましたが、代わりにPCIeSSDを搭載することを選択しました。
これにより、IO完了時間が100分の0.02に短縮され、書き込みの場合は2ミリ秒になりました。これは、以前の約XNUMXミリ秒ではありませんでした。
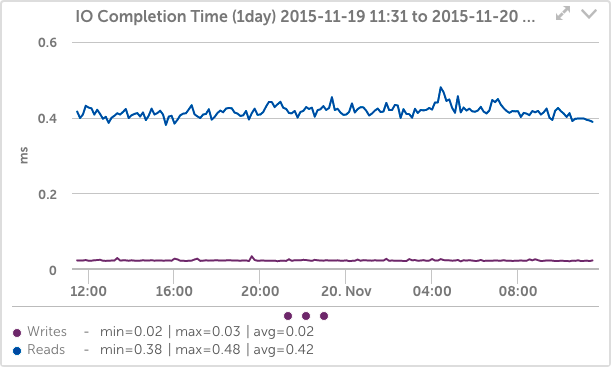
もう10,000つの興味深い注意点は、書き込みの数が、同じワークロードで、12,000秒あたり約22,000の書き込み(約XNUMXのマージ)からXNUMXの書き込み(XNUMX秒あたりのマージなし)になったことです。 間違いなく、これはPCIenvmeディスクが なし SATA SSDが使用したデフォルトのCFQスケジューラーの代わりに、カーネルIOスケジューラー。 (私がしたように 前に述べた、これはテストが簡単で、以前のSSDに対してさまざまなスケジューラーをテストしましたが、検出可能な違いは見つからなかったため、デフォルトのままにしました。)
私たちが指摘したさらに問題な問題は、NVMEディスクがLogicMonitorとIOstatの両方で、100%のビジー時間と、数十億のキューサイズを報告したことです。 ただし、古いカーネルが原因で、これはカーネルの問題であることが判明しました アトミックな機内カウンターを使用しない。 カーネルが更新されると、統計は正しく報告されます。
では、デバイスの使用率はPCIe SSDのドライブパフォーマンス容量の優れた予測因子になるのでしょうか、それとも同時に要求を処理できるということは、計画のためにそのメトリックに依存できないことを意味するのでしょうか。 ええと、私たちはこれらのデバイスの100%にはほど遠いです、そして私たちはまだ正確なワークロードシミュレーションを実行していません
このスケール–しかし使用 FIO、これらのカードをほぼ100%に駆動するために、多くのワークロードスレッドを実行する必要がありましたが、遅延も増加することがわかりました。
ただし、いつものように、システムのスケーリング方法を最もよく示すのは、システムをスケーリングするときに、システムにとって重要なメトリックを監視することです。 ドライブの使用率は指標ですが、アプリケーションのカスタムメトリック(たとえば、独自の内部キュー、遅延、または適切なもの)を監視するほど意味はありません。 アプリケーションが重要なメトリックを公開し、監視システムがそれらをキャプチャするように簡単に拡張されていることを確認してください。 ただし、デバイスの使用率などの指標も引き続き取得します。データが多いほど常に優れています。